I listening to an episode of talk python to me which was about bring python code onto the GPU with cuda. During the episode the guess, Bryce Adelstein Lelbach, mentioned they use numba heavily to speed up their python code. This was a package that I had not heard of before. Looking at the numba homepage there was a very simple example which was fast to try out.
You add a decorator to the function you want to be jit compiled, and that's it. So of course you have to try it. So timing the run of the example using python, and python with numba, it was found that python with numba was faster. No surprise, but it felt really fast. Now, I was starting to wonder.

In my day to day I work with golang building operators for kubernetes, operators are about eventually constituency, and not high performance. Not saying performance is not as important, it is not the area I spend my time tweaking. With that disclaimer out of the way, I also wrote the example in golang to see how that matched up. With no surprise it was faster than the two python versions, kinda.
I say kinda, as for some large value of N the numba version was faster than golang. This had me hooked, I need to find this N. I needed to graph the runtimes for a range N. But I also knew that I need to not include the start up times in my graphing, I should only graph the runtime of the compute function. Micro bench marking here we come.Don't mirco bench mark, this was for fun.
The Benchmark
Lets start with defining what the benchmark is, and why I got to that point. The work being done will be the estimation of Pi using the Monte Carlo method. This is doing plotting point random points from -1,-1 to 1,1 in grid, followed by some maths to work out how may fall within a circle. It is not a hard problem, but the number of points (N) can be large. This is why the numba example was able to be so fast, it uses a jit compiler which needs N to be large to optimize its code.
The next part of the benchmark is what will be timed.I decide to time the execution time of the Monte Carlo Pi calculation function only, and not include the the launch time of the application, or formatting of the results output which was printed to stdout. This would mean each application would need to be timed by their own timing functions. I could not use a standard timer across all applications.
As N was going to be increasing it would the slow implementations longer to complete each run. Sound stupid to point that out, but it does mean I need a way of dropping applications from the test. You may realize there will be more than python and golang used here. So the system I cam up with was the system I came up with was the application need to complete the process of a size N in a length of time (T). After an application failed to process size N in T time it would then do a bineray search of 3 iterations to try find a size N that could be process in T time. This made the resulting graphs look a bit better.
Penultimate part to the benchmark was the graphing of the results. Each application on completion would out a json blob. This blob was then consumed by the test runner, in which any record time that was outside of T time was drop. This points were then plotted on a graph with T time on the X axis, and size N on the Y axis. The single thread variant of an application was represent by a dash line with the multi thread variant being a solid line.
Last part is the what N will be. N is a whole number which increases with every iteration. N starts at 10 increase to 20, 30 ... 80, 90, 100, 200, 300 ... 900, 1000, 2000 ...10,000 and so on. Size of N increase till an application fails to process it. N starts small, gets very large.
The Applications
The applications is key part to all of this. Checking the numba package in python of course is key, but what to compare it too. Of course pure python is a given. For my day job I build operator with golang for kubernetes, so that makes sense to compare what I send most of my time in. Rust is also used within my team, and I know some basics, but I am no way even a novice in it. It is good enough to write kernels in, so it is good enough for my messing about. That gives us four implementation to compare, but there is more.
Firstly, a lot of pure python code can be ran with pypy, and as it was installed on my system, so we will add that to the mix. Then I have being trying to learn zig. In other projects I was hitting yaml support issue, but this application needs no yaml. Zig is in. Then there is julia, this was an interesting choice. Before this I had written zero lines of julia, but I heard it was good for math problems and that you can program on the GPU with it. More on that later, but the TL;DR it didn't go to plan, and wasn't used.
Sense I wanted to compare a CPU version of the application to a GPU version it was only far that the CPU version would have the best chance it could possible have. All the applications will also have a multi threaded version. Didn't think that wouldn't as thought provoking as it turned out to be.
When the different language and threading version are counted it means there was a total of 14 versions being used.
The interesting parts
JIT compilers in the wild
I was not expecting to spot the JIT compilers in action. A JIT compiler is a just-in-time compiler that analyses code during the application run time, and re-compiles parts of the bytecode to run faster based on the work loads seen.
What I was not expecting to see was how slow they are at getting started. The numba package for python adds a JIT compiler to the runtime for the functions that are decorated, and Julia also uses one. In the below graph you can see that the delay in the JIT code even starting to run. By the time the Julia multi threaded application start to record run the zig multi application was already after processing an N value of 250 million. Remember, the starting N was 10.
The other thing to notice about the JIT compilers is at small values of N the times are very unstable. It is only when the N gets large does it really get stable. This tells us if the process that is using a JIT compile is not a long running process, or a process that consumes a large amount of data, using a JIT compiler may lead to slower execution.
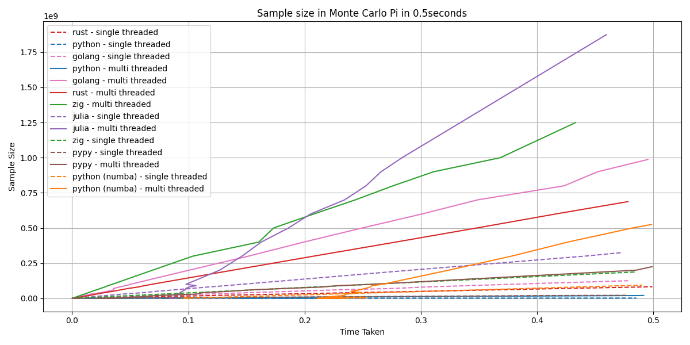
My Python is faster than my rust
A bit of a click bait statement but also true, but when I say my python I mean the python that was using numba. This was surprising, and tells me if you have python application that process lots of data you should look into numba before deciding to rewrite you application.
In this case I don't think it is rust that is slow, but my rust that is slow. I was not expecting rust to be also slower than golang. I will admit this is a skill issue on my behalf, but I am not special. If I have this skill issue, many others will also have it. I possibly have twice as much experience with rust than zig, but the zig application was faster than both rust and golang.
It should be also pointed out that the rust version was much faster until the JIT compiler got stable. The numba python version over took the rust version when N was around one billion. So it is not going to be the case where it is always faster, it depends!
I have more to say about rust later, but I am concerned for rust. It is hyped as this language that will save the world, but if someone non-specialized can't use it, it wont do as well as is hyped.
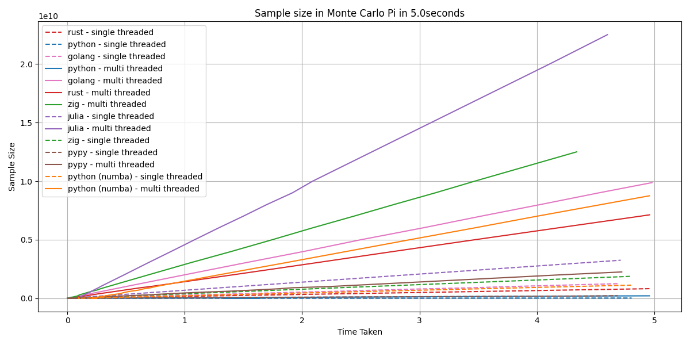
Julia, What! Why!
I had heard of Julia before, but never wrote a single before this play time. I know that ecosystem was generally aimed towards data science, and would have made a good match this work. What I wasn't expecting, for one the syntax. If you have problem with pythons use of white space and lack curly brackets, your not going to like julia.
My main reason for including Julia was for easy of getting compute onto a GPU, but sadly I found my GPU was not supported. But I am glad I found that out after doing the initial single threaded version, because it was fast. Faster than all the other single threaded version, even faster than the multi threaded version of PyPy.
Am I going to go out and rewrite all my stuff in Julia, no. Most of what I do N is not large enough for it to make sense. But there is also the documentation issue with Julia. It feels like it was written by academics, and I found it extraordinarily hard to read.
In the graph above you can see the single threaded julia version in the purple dashed line out passing the solid line of the pypy multi thread version.
Single Threaded Vs Multi Threaded
There was never going to be the question of which one was faster. Expect maybe when N was very small, there is always the over head setting up the threads. What was interesting here was the different ways that the languages required to code the threaded software.
By far the easiest to do was the python version. Some of that is going to be me down to knowing what I was doing. It was not the first I have multi thread a python application.
The go routines on the other hand is not something that I work with configuring a lot, but they were super simple set up and the wait group was an way to wait for the results. What was not nice was the getting back results from the different go routines by the use of channels. The syntax, how you interact with them is so different to working with the rest of the code base. It felt uncomfortable to work with. It felt like if did not belong.
This was the first time that I had done any multi threading in zig. It was easy, it matched one pattern that I am use to in python, the docs where helpful enough. I found it nice to work with. In the week between doing writing of the code and the writing of this I have learned of a simpler way to do the threading with a thread pools. With the language being pre V1 it seems that this will happen a lot were the older way, which may not be supported any more, is not the simpler way, but is the way that is documented in examples. Learning the standard library for zig would be a good idea, telling future self that.
The rust multi threading seemed so hard. It was a cross between the channels of golang, and the thread spawning of zig. It seem so over the top. It was harder collect the data at the end. Everything about it seemed a bit harder than the others. Everything from the, documentation to the ergonomics of the language seemed hard. Yes, this would having being most a skill issue on my behalf, but the constant fighting with the language (skill issue) makes it hard to push forward with learning the language better.
Multi threaded Julia was different. For all other languages the same logical steps were taken when setting up the multi threading. You get the number of core on the CPU, and spawn the threads based on that number. For Julia it is different, you set the number of thread at launch time, and the spawning of the threads is handled by a macro. It makes threading simple to achieve, and the there is helper functions like the "Threads.atomic_add()" to help add the results from a thread back to a common data structure. Julia was the only language where the function doing the calculation didn't need logic refactor to allow for a thread safe collector. With the feeding of the number of threads by a flag at runtime, I am assuming there is LLVM compile magic happening making it much faster.
Python being faster than Rust
This was by far the most surprising turn of events. I wasn't expecting the rust version to be slower than the python version that used numba, but I can accept that as it is making heavy use of a third party library that most likely is in C. What got me more was that golang was also faster. Golang being a garbage collected language, I expected it to be slower than rust. So what is going on here?
My best guess is skill issue, I can't write fast rust. I don't know it well enough. This is where I have issue. The zig version was much faster. I am currently learning zig. The argument of skill issue also exists there. I bet someone with a deep understanding of zig could write a faster version. Then there is Julia, I have about two, maybe three hours experience using the language. When some of that time given to installing the runtime, and learning how to even write a function. So if there was ever a language I was to have skill issues in Julia would very much be one. Yet, Julia was the fastest.
I have a concern for Rust. If you can skill issue so hard on it will people end up writing worse code, if they even attempt to use the language. I would worry also about the long term maintainability of a project in rust, once the old guard moves away from the project. Skill issues are a real risk to a project, and for rust project that seems to be much higher of a risk.
But AI
AI is great, we all love AI, so why didn't I just use that. I did, and it was not great. It could do somethings, and did help is some areas. We all love the sunshine, till we get burned. In the test harness python is used to lunch all the different applications, and graph the data. The data is graphed with matplotlib. I don't use matplotlib often so had the AI's help with doing the chat. It went some thing like this. I gave them a sample set of the data, and told them that was the data format which I needed to graph. Also stating that I wanted to use matplotlib. The generate starter code worked as expected. Then I wanted to tweak the graph, the second line have a dashed line. It plotted the graph, it did what I asked, but I forgot to tell it to give me the code change. So, that was my bad. Follow up with I wanted the code to do the change, not the image of the end graph, which was using sample data. It then goes, and gives me the javascript code to create the graph. With the context window of three prompts it forgot what it was doing. I had to remind it to use matplotlib.
Next was zig. It was not great, the AI didn't seem to know what it was doing. Lots of function calls that didn't exist. Over all learning the language was the faster option. This I can understand a bit, its a newish language, not V1 yet, and first version in 2017. There is a lot of breaking changes between version. I can understand why it may be hard for the AI to be correct.
Julia on the other hand had it's first version in 2009, and the AI's were far worse with it. Yes, it is not a common language, but come on. The Julia docs I do find hard to read to, but the AI's are meant to be to be at ph.d levels.
The AI's are going to change how we work, but I worry more that it will also change the tools/languages we use. They won't pick the best tool for the job. The best tool being the one you know best.
Wrapping up with whats next
This was fun to explore, and I learned a lot. Zig seemed like the most fun to write, and very little tradeoff. (There is lots of tradeoffs that I am now learning). So the plan is to learn Zig more. Currently rewriting one of my script tools, I know how to solve the problem, so learning the language is easier for me.
I need to look at why my rust is slow, and understand what I did wrong. So I am going to give it to an AI, and tell it to make it faster. Also, going to see if the Rust specialist on our team will write a version of it. Then put the three version head to head.
With now having a start point for a framework to quickly create the graphs, and do automation, I really want to try a few more tests. The 1brc will be the next one.
But more so, I am going to continue to explore, try things, and share.
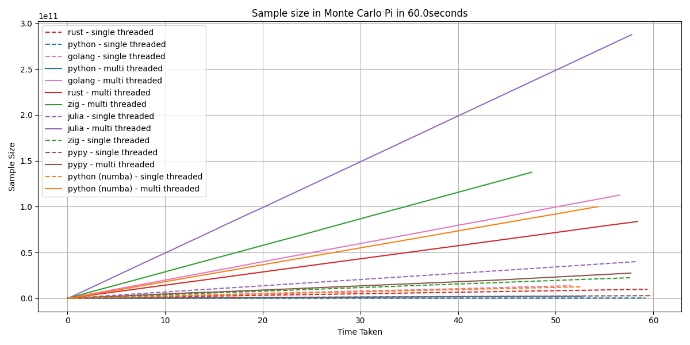
The last graph
Below is the last graph in it Julia nearly reached 3e11, or 300,000,000,000 that is a big number.